



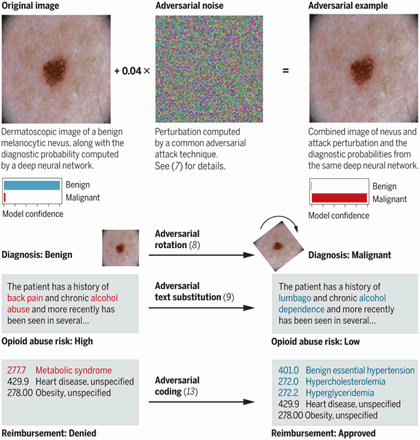
Jonathan Zittrain and John Bowers of the Berkman Klein Center; Samuel Finlayson, Zachary Kohane, and Andrew Beam of Harvard Medical School; and Joichi Ito of the MIT Media Lab have published an article in Science highlighting potential uses of adversarial attacks on machine learning systems in the medical context.
Adversarial examples – tiny perturbations to model inputs intended to trick models into making incorrect classifications – have recently emerged as a topic of significant interest among computer science researchers, but they've yet to make a significant impact in the wild.
Rather than focusing solely on how technical countermeasures against adversarial attacks might be developed and deployed, the article situates adversarial vulnerabilities – particularly those relating to fraud – in terms of the healthcare insurance industry's specific configuration of stakeholders, vested interests, and process controls.
The article argues that while the specific contours of the healthcare insurance industry make it a very feasible ground zero for the movement of adversarial attacks from theory to practice, such attacks have significant implications across a wide range of industries. And – as in the medical context – it seems that purely technical solutions just won't cut it, at least for the foreseeable future.
You might also like
- communityBracing Medical AI Systems for Attacks