MediaCloud
Overview
Media Cloud is a system that lets you see the flow of the media. The Internet is fundamentally altering the way that news is produced and distributed, but there are few comprehensive approaches to understanding the nature of these changes. Media Cloud automatically builds an archive of news stories and blog posts from the web, applies language processing, and gives you ways to analyze and visualize the data.
Media Cloud is aims to tracks news content comprehensively – providing open, free, and flexible tools. This will allow unprecedented quantitative analysis of media trends. For instance, some of our driving questions are:
- Do bloggers introduce storylines into mainstream media or the other way around?
- What parts of the world are being covered or ignored by different media sources?
- Where do stories begin?
- How are competing terms for the same event used in different publications?
- Can we characterize the overall mix of coverage for a given source?
- How do patterns differ between local and national news coverage?
- Can we track news cycles for specific issues?
- Do online comments shape the news?
Media Cloud is capable of crawling and analyzing arbitrary on-line news media and blogs. At the high level, we monitor RSS feed updates and then direct our crawler to download the corresponding web pages. These web page are saved and then later analyzed. Among other types of analysis, we currently do entity extraction, word frequency analysis, and clustering. But we are open to other types of text analysis ideas.
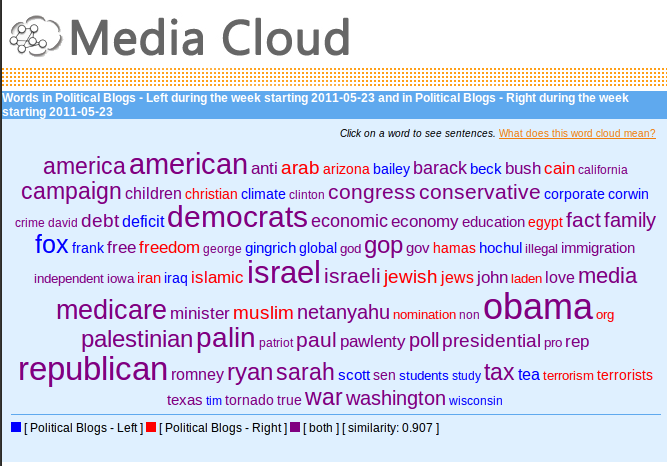
The main site for Media Cloud is http://www.mediacloud.org.
There, you can see some simple visualizations generated out of our system, but the project is under very active development and there is much more under the hood. Applicants are encouraged to examine the source forge project page and subversion repository.
Skills Needed
Essential Skills
- Perl - The Media Cloud code base is largely Perl so at least some familiarity with Perl is essentially.
- SQL/Database - We use a Postgresql database backend to manage the large amount of data that Media Cloud processes. So a knowledge of SQL is also important. Experience with Postgresql would be ideal but someone with exposure to other databases such as MySql or Oracle could probably get by.
- HTML/Javascript/Jquery - The web based front end portion of Media Cloud uses JavaScript and JQuery extensively. For projects that involve the front end, students should have at least some knowledge of JavaScript, JQuery, and HTML. Obviously, this will be less important for students working primarily on data analysis projects.
Useful Skills
These skills would be significant pluses but not necessary skills for students who want to work on Media Cloud
- | Natural Language Processing (NLP) - Some exposure to NLP would be very useful in helping students understand and contribute to Media Cloud.
- Big Data - Media Cloud is designed to process large amounts of data. Our main database is nearly a terabyte in size and we have downloaded hundreds of gigabytes of articles. One of the challenges in Media Cloud is designing queries that run quickly on large amounts of data.
- Data analysis - One of the challenges in Media Cloud is making sense of the data that we gather. Therefore, exposure to data analysis or statistics will be a plus.
- Visualization / Design - Often data can best be understood visually. For students working on the front end, knowledge of design and visualizations will be a plus.
- Media Analysis - Media Cloud was developed to make sense of the changing news landscape. Thus some knowledge of media studies or media analysis would be useful. GSoC projects are technical in nature so this is in no way necessary. However, some basic knowledge of media analysis may be useful, particularly for projects that focus on data analysis.
Ideas
CPAN Module Creation
There are a number of pieces of the Media Cloud source code which could be useful to other programs. A student would go through the Media Code base and work to turn as much code as possible into CPAN modules so that it could benefit the larger Perl community. The ideal applicant would be familiar with the creation of CPAN modules but a student who's knowledgeable on Perl in general could likely learn about CPAN module creation during the summer.
Linux Distribution Packages
We have worked extensively to make Media Cloud easier to install but the process is still less automated then we would like. We would like to create Linux distribution packages that would allow Media Cloud to be installed simply by downloading package file(s) (e.g. .debs) and using a package management tool such as | apt-get. We are most interested in supporting the Ubuntu / Debian architecture. Packaging a large system like Media Cloud is surprisingly difficult due to the large number of external CPAN module dependencies. Thus a successful project could serve as an important reference for the wider Perl community. The ideal solution would have the following features:
- Automated Package Generation - There should be a simple automated process to generate new packages when we wish to update our distribution. This could be a script or some other process.
- Support For Modules Not Packaged By OS Distributor - Media Cloud depends on many modules that are not included in the distribution packages. For example, Media Cloud depends on the Algorithm::Cluster module which is not included in the Ubuntu package.
- Module Version Consistency Between OS Versions - Installations of Media Cloud on different versions of an operation system should use the same CPAN module versions. For example, installs of Media Cloud on both Ubuntu 11.04 and Ubuntu 12.04 should use the same version of the Catalyst CPAN module.
- Control Over Module Versions - Media Cloud developers should be able to control which versions of CPAN modules Meda Cloud uses. In other words, the developers should be able to use versions that are different (newer or older) than what the OS vendor distributes. For example, developers might wish for Media Cloud to use version 9 of Catalyst even if the OS vendor only packages version 8. Conversely, the developers might wish that Media Cloud use version 8 of Catalyst even on systems in which version 9 is distributed as a vendor package.
- Support For Perl Versions Different Than the System Perl - We may want to be able to require that Media Cloud uses a newer version of Perl than is distributed by the OS vendor. For example, we might want Perl 5.14.2 to be used by Media Cloud on systems in which the system Perl is version 5.8.
The last few requirements strongly suggest packaging Media Cloud with Perl libraries that are separate from the standard system Perl packages. However, we would be open to other approaches. Our current approach uses perlbrew and Carton so applicants should make themselves familiar with these tools.
Web API
Currently Media Cloud allows simple queries through a public web interface and also allows very large data dump files to be downloaded. However, the creation of a web api would allow Media Cloud comment to be used more easily and richly. Possible challenges include: allowing rich queries without overly taxing the underlying system and determining what data is most interesting to others.
Multi-language Support
Our system was originally designed to work with English language sources. We have since done significant work to internationalize the code (internally everything is stored in UTF-8). We currently have some support for Russian and limited support for Chinese. But we would be very interested in projects to extend Media Cloud to support other languages. This would likely require the student to have fluency or at least proficiency in the language they wanted to add support for. Among other things this would involve adding support for stemming and stop words for the additional languages.
Data Visualizations
Often large amounts of data can best be understood visually. We are interested in students who would like create new visualizations for Media Cloud data or improve existing visualizations.
Allow Rich Queries
We have terabytes of data and millions of archived stories. How can we construct queries that work efficiently on this data set and generate interesting and compelling results? For instance, we are currently experimenting with time-sequence analysis of different terms across different media sources (see, for instance, our experimental charts of coverage of the bailout. How would we go about visualizing some of these questions with the data we have? We currently use the Google Visualizations API to actually generate our charts.
The other idea in this area is to help us develop a rich API to allow others to access our data. This is a high priority for us, but we need help. If you worked with us in this area, you would have quite a bit of latitude to help us define the queries, language, etc.
Suggest Your Own Project
Applicants are encouraged to suggest other projects whether some combination of the ideas above or something else entirely.
Mentor: dlarochelle@cyber.law.harvard.edu
General Questions: berkmancenterharvard@gmail.com